(25 Qs Updated December 2025)
This page shows a test of many Kikuyu speech‑to‑text and Kikuyu→English systems.
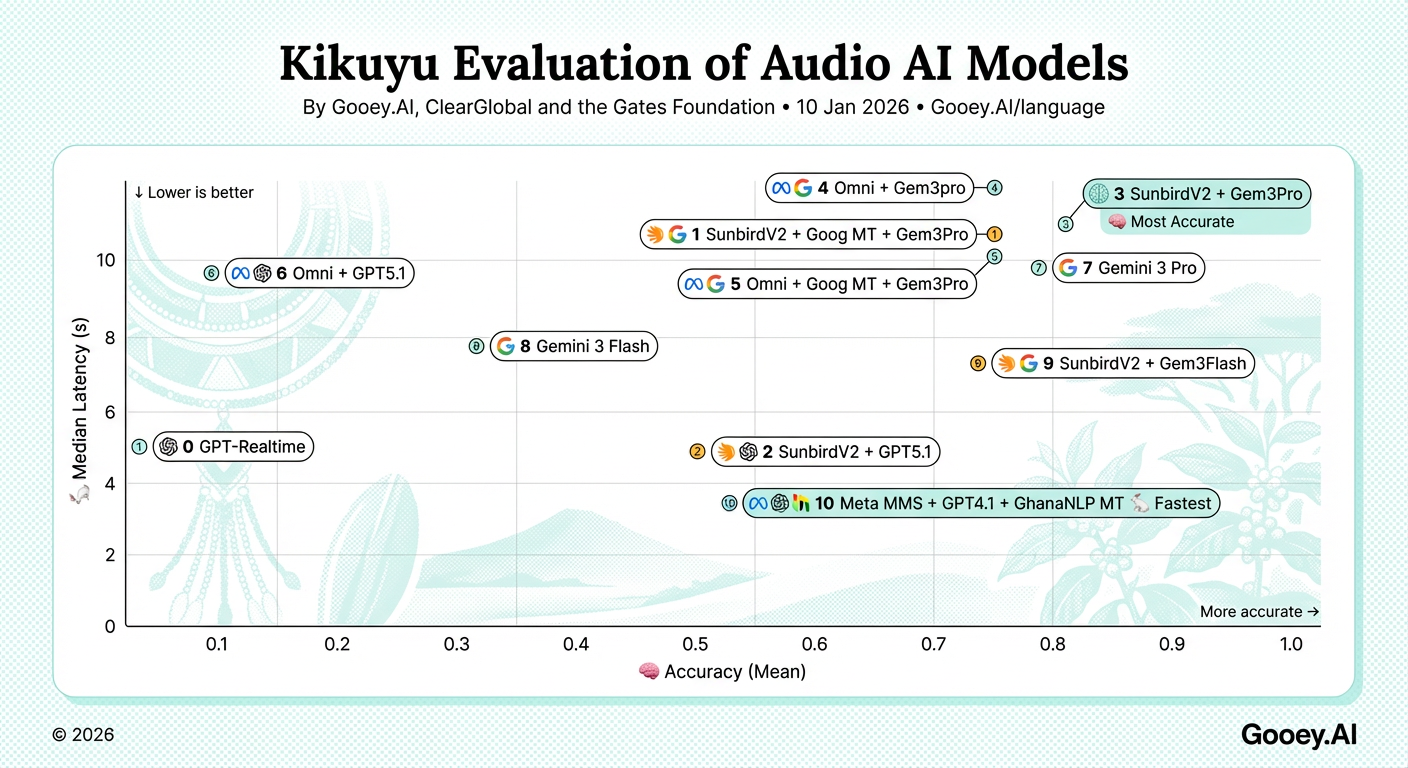
We use the same Kikuyu audio for every system. Then we compare each system’s text to a reference answer and give it a score between 0 and 1.
A higher score means the system is closer to the reference text and usually more accurate.
Ranking Table
| # | Workflow | Accuracy (Mean) | Median Latency (s) |
|---|
| 0 | GPT‑Realtime | 0.05 | 5.06 |
| 1 | SunbirdV2 + Goog MT + Gem3Pro | 0.78 | 12.38 |
| 2 | SunbirdV2 + GPT5.1 | 0.57 | 4.85 |
| 3 | SunbirdV2 + Gem3Pro | 0.83 | 11.96 |
| 4 | Omni + Gem3pro | 0.78 | 13.84 |
| 5 | Omni + Goog MT + Gem3Pro | 0.74 | 12.75 |
| 6 | Omni + GPT5.1 | 0.18 | 9.73 |
| 7 | Gemini 3 Pro | 0.81 | 12.02 |
| 8 | Gemini 3 Flash | 0.38 | 7.80 |
| 9 | SunbirdV2 + Gem3Flash | 0.75 | 7.23 |
| 10 | Meta MMS + GPT4.1 + GhanaNLP MT | 0.56 | 3.69 |
You can use this page to:
- See which system gets the best score
- Compare different models and pipelines side by side
- Choose the best system for your app, research, or product
- Download all results for deeper analysis